
Abstract: 本文介绍SVD,奇异值分解,应该可以算是本章最后的高潮部分了,也是在机器学习中我们最常用的一种变换,我们经常需要求矩阵的特征值特征向量,比如联合贝叶斯,PCA等常规操作,本文还有两个线性代数的应用,在图像压缩上,以及互联网搜索上。
Keywords: Singular Value Decomposition,JPEG2000,Eigenvalues,Eigenvectors
SVD分解
今天的废话关于学习知识,最近看到一种说法,我觉的非常的形象,有个大神(是谁我忘了),他说已知的知识像一个圆圈,而自己能感受的未知就是紧邻圆圈,圆外部的区域,当你知道的知识越来越多,圆圈不断扩大,圆周也随之扩大,所以你会越来越发现自己无知,那么就会更努力的去学习,所以越有知识的人越谦逊,尤其是对待知识上,尊重知识,探索未知领域是人类文明存在的根本动力。
奇异值分解 (Singular Value Decomposition)
SVD,熟悉的名字,如果不学习线性代数,直接机器学习,可能最先接触的就是SVD,所以我记得在写上个系列的博客的时候(CSDN,图像处理算法)就说到过SVD,当时还调侃了下百度,每次搜SVD出来的都是一把枪(报告政府,这个枪是穿越火线里面的,没超过1.7J)
这张分解图是我无意中发现的,ak47的发明人说过,如果一把枪,零件已经精简到最少了,那么这个才是精品,类似的意思上篇博客也说过,矩阵变换到最简单的形式,能够体现出其最重要的性质。
SVD,奇异值分解,与QR,LU,$S\Lambda S^{-1}$ 等变换类似,其经过变换后会得到一个结构特异性质非凡的矩阵,SVD分解的结果和形式与对角化都非常相似,只是在形式和思路上更复杂,或者说如果说Jordan 是矩阵的对角化的扩展,因为有些矩阵特征向量不完全,那么SVD也是对角化的扩展,因为有些矩阵并不是方的。
所以SVD也是对角化,并且拥有比 $A=S\Lambda S^{-1}$ 更完美的性质,但却是也复杂了一些,$A=S\Lambda S^{-1}$ 有以下几个问题,需要完善:
- S中特征向量一般不是正交的,除非A是对称矩阵
- A并不是总有足够的特征值,这个是Jordan解决的问题,多个特征值相等,其对应于一个特征向量的时候,Jordan可以写成一块一块的对角矩阵
- A必须是方的方的方的
Singular Vectors作为eigenvectors 的替代品,可以完美解决上述问题,但是作为代价,我们的计算过程会变得复杂,并且Singular Vectors有两组,$u$ 和 $v$
$u$ 对应的是$AA^T$ 的特征向量,因为 $AA^T$ 对称,所以 $u$ 们可以选择相互正交的一组。
同理 $v$ 对应 $A^TA$ 的特征向量,因为$A^TA$ 对称,所以 $v$ 们也可以选择相互正交的一组。
这里注意是选择,因为你也可以选择不正交的,但是不正交的可能就会很麻烦了。
铺垫的差不多 ,然后我们有下面的这条重要性质,为什么会成立后面有证明,现在就告诉你SVD究竟是个啥子鬼:
$$
Av_1=\sigma_1u_1\\
Av_2=\sigma_2u_2\\
\vdots\\
Av_n=\sigma_nu_n\\
$$
$v_1,\dots,v_n$ 是$A^TA$ 的特征向量,所以 $v$ 是矩阵A的Row Space
$u_1,\dots,u_n$ 是$AA^T$ 的特征向量,所以 $u$ 是矩阵A的Column Space
$\sigma_1,\dots,\sigma_n$ 全部为正数,称为矩阵A的奇异值。
然后下面我们把 $u$ 和 $v$ 组合成矩阵 $U$ 和 $V$ ,那么根据对称矩阵的性质,$U^TU=I$ 同理 $V^TV=I$ 那么接下来我们来组合一下:
$$
AV=U\Sigma \\
A
\begin{bmatrix}
&&\\
v_1&\dots&v_r\\
&&
\end{bmatrix}=
\begin{bmatrix}
&&\\
u_1&\dots&u_r\\
&&
\end{bmatrix}
\begin{bmatrix}
\sigma_1&&\\
&\ddots&\\
&&\sigma_r
\end{bmatrix}
$$
矩阵形式就是这样喽,没什么解释的,就是上面计算的组合形式,但是注意这里有个很重要的参数,$r$ 没错,就是矩阵的rank,这里rank表示了矩阵A的Singular Values的数量,所以上面计算从规模上是:
$$
(m\times n)(n\times r)=(m\times r)(r\times r)\\
m\times r=m\times r
$$
从矩阵相乘的规模上也能看出等式没有问题,但是这个r有的问题,可以肯定的是,有效的Singular vector有r组,但是这样与原始矩阵形状差的有点多,那么就补一补,虽然补的都是没用的,但是也算是整齐划一了,首先 $\Sigma$ 中缺少的只能补0 ,所以对应的V就只能补A的Nullspace了,因为这样 $AV$ 的补充部分是0,同理,为了配合V,U添加的是left nullspace,并且这些添加的无用值也要选择orthonormal的,以保证$U^TU=I$ 和$V^TV=I$。
其实这里隐藏了一个重要的知识点,就是四个空间的那课,矩阵的rowspace和nullspace正交column space与left nullspace正交,而V本来是A的行空间正交基,那么添加的一定是Nullspace中的正交基,以保证矩阵正交,所以完美结合,(如果忘了四个空间点击查看)
所以更一般化的表示:
$$
AV=U\Sigma \\
A
\begin{bmatrix}
&&\\
v_1&\dots&v_n\\
&&
\end{bmatrix}=
\begin{bmatrix}
&&\\
u_1&\dots&u_m\\
&&
\end{bmatrix}
\begin{bmatrix}
\sigma_1&&&\\
&\ddots&&\\
&&\sigma_r&\\
&&&
\end{bmatrix}
$$
规模上是,注意 $\Sigma$ 不是方阵:
$$
(m\times n)(n\times n)=(m\times m)(m\times n)\\
m\times n=m\times n
$$
$\Sigma$ 被填充成立 $m\times n$ 通过在矩阵中加入0来实现,新的矩阵U和V依旧满足 $V^TV=I$以及 $U^TU=I$
那么我们的A就可以分解了
$$
AV=U\Sigma\\
for:\;VV^T=I\\
so:\\
A=U\Sigma V^T\\
SVD\,\,\, is:\\
A=u_1\sigma_1 v_1^T+\dots+u_r\sigma_r v_r^T
$$
其中$u$ 是$m\times 1$ 的 $v^T$ 是 $1\times n$ 的,所以A是 $m\times n$ 的没有问题,并且所有 $u_i\sigma_r v_i^T$ d的rank都是1,这就是Sigular Values Decomposition了,这里反复的验证规模的原因是因为A不是方阵,所以,在做乘法的时候要非常小心矩阵规模。那个小的只有r个有用值的SVD我们叫他reduced SVD(其实我觉得这个更有实际意义,毕竟这里面才有最重要的信息,新增的那些最后奇异值都是0了,也就没有啥作用了)可以表示为:
$$
A=U_r\Sigma_r V_r^T
$$
写了这么多,我们到现在还不知道Singular是怎么计算出来的,那么我们先给出结论,后面继续证明:
$$
\sigma_i^2=\lambda_i
$$
其中$\lambda_i$ 是$A^TA$ 和$AA^T$ 的特征值。
那么要问$A^TA$ 和$AA^T$ 拥有相同的特征值,为什么?
这个我真没想明白怎么证明,所以这个地方算个坑,会了再回来填
然后我们得到Singular Values后,我们把他们按照从大到小的顺序排列,然后写成上面SVD的形式:
$$
\sigma_1 \geq \sigma_2 \geq \sigma_3 \dots \geq \sigma_n
$$
下面举个小🌰 :
什么时候SVD和对角化相等?
当A是半正定或者正定矩阵的时候,$S=U$ 并且 $S^T=V^T$ 此时 $\Lambda=\Sigma$ ,因为正定矩阵特征值为正,而且是对称的,所以 $U=V=Q$
下面介绍一个应用,大应用,为什么我会把这个应用写出来呢?因为他和图像有关,所以我们可以简单实践一下,还是从感性上认识一下SVD,然后再理论上完整的证明一下。
图像压缩 (Image Compression)
在介绍SVD之前,我们先来分析一个问题:图像的存储空间,一个图像假如是512x512的大小,灰度图像,每个像素占一个字节的话,这张图片那么会占据硬盘262144个字节,也就260多k个字节,如果按照23帧每秒,十秒钟大概要60兆,一分钟大概3.6G,在想想这个尺寸这么小,我们看的一般都是720P的,这样算的话硬盘根本不够用,一个东京热以后就再也不能一本道了,所以必须要压缩一下子,怎么压缩呢,这里介绍下JPEG的一个大致思路,就是矩阵分解:
$$
A=u_1\sigma_1 v_1^T+\dots+u_r\sigma_r v_r^T\\
A=\sigma_1 u_1 v_1^T+\dots+\sigma_r u_r v_r^T\\
A=\sigma_1 S_1+\dots+\sigma_r S_r\\
where:\,S_i=u_i v_i^T
$$
这样就是按照singular的大小,给所有singular vector排序,奇异值越大证明这个奇异值向量对原始数据影响越大,所以这两奇异向量组成的这个基就越重要,当然要提前加进去,所以我们如果选择一部分奇异值和奇异向量,比如$N=100$ 也就是200个奇异向量和100个奇异值,那么一共是$200\times 512+100=102500$ 比原来的260k减少了一半,如果用的更少那么减少的更多,当然图像质量也就有所损失了,写了个python程序,可以观察一下:
使用多组S来还原原始数据,使用S越多还原度越高,但需要的存储空间就越大,S就是上面$u_iv_i$的结果,可以看做图像的一个切片,视频中第一幅为原图,第二幅为若干张S相加得到的结果,最后一张是他们之间的差,我们可以暂时理解为压缩误差。
视频演示地址http://player.youku.com/embed/XMzE5NTIyNjQ4MA==
代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26import cv2
import numpy as np
from numpy import linalg
import copy
N=500
image=cv2.imread('lena.jpg',0)
cv2.imshow('src',image)
U,Sigma,V=linalg.svd(image)
sigma_size=len(Sigma)
image_s=[]
waittime=0
for i in range(N):
if i>sigma_size:
break
image_s.append(U[:,i].reshape(len(U[:,i]),1)*V[i]*Sigma[i])
if i>0:
image_s[i]+=image_s[i-1]
print 'total: ',i,' Singular Value'
show_image=copy.deepcopy(np.uint8(image_s[i]))
font = cv2.FONT_HERSHEY_TRIPLEX
cv2.putText(show_image, `i`, (10, 500), font, 4, (255, 255, 0), 1, False)
cv2.imshow('Compression',show_image)
cv2.imshow('Different',np.uint8(image-image_s[i]))
cv2.waitKey(waittime)
waittime=100
上面公式中每个S都是一个rank=1的矩阵,如果两个这样的矩阵相加,rank就变成了2,n个相加就是rank=n,所以SVD分解后再组合有点像切片,每一片都是有规律的,同样的道理,SVD换成小波,那就有了JPEG2000,小波的基矩阵也是满足一些特殊性质的,后面可能会将,但是不确定,所以数据压缩可以理解为最关键的一步就是两个向量相乘,能够得到一个矩阵,这个矩阵组成了基础的片,然后多个片加权求和就得到了还原数据。
SVD的应用应该非常多这里就写了一个,比较重要直观的,下面还是要继续研究原理。
基和SVD(The Bases and the SVD)
书中并没有给出严格的证明和推到过程,老爷子还是走的启发式套路,我们来从基开始看,假设一个矩阵A是个2x2的矩阵,这样比较好计算,并且A是非奇异矩阵,也就是A可逆,rank=2,span成整个 $\Re^2$ 空间,那么我们应该可以找到两个向量正交的单位向量 $v_1,v_2$ 满足 $u_1=\frac{Av_1}{|Av_1|},u_2=\frac{Av_2}{|Av_2|}$ 使得$u_2$和$u_1$ 正交,并且是单位向量,那么就有:
$$
A
\begin{bmatrix}v_1&v_2\end{bmatrix}=
\begin{bmatrix}Av_1&Av_2\end{bmatrix}=
\begin{bmatrix}|Av_1|\cdot u_1&|Av_2|\cdot u_2\end{bmatrix}=
\begin{bmatrix}u_1&u_2\end{bmatrix}
\begin{bmatrix}|Av_1|&\\&|Av_2|\end{bmatrix}\\
AV=U\Sigma
$$
总结下,这个构造基的过程是瞄准了目标去的,也就是说目标就是类似于构造 $Ax=\alpha y$ 形状的一种形式,但是x和y要满足不同的关系,如果相等那么就是特征值,如果不相等就可以构造出多组相互正交形成奇异值,并且通过上面的构造过程,我们可以得知奇异值等于缩放u到单位向量的缩放比例 $|Av|$
其实可以用一种更直观的方法解答SVD的存在:
假设对任意矩阵A存在分解 $A=U\Sigma V^T$ 并且其中$U^TU=I$ $V^TV=I$ 那么我们要证明U和V的存在即可:
$$
A^TA=(U\Sigma V^T)^T(U\Sigma V^T)\\
A^TA=V\Sigma (U^TU) \Sigma V^T\\
A^TA=V\Sigma^2 V^T
$$
虽然A不是对称的,但因为$A^TA$ 是对称矩阵,存在正交矩阵Q使得 $A^TA=Q\Lambda Q^T$,那么这时候的V就是 $A^TA$ 的Q这个是没问题的,至于 $\lambda_i=\sigma_i^2 \geq 0$ 成立的原因是 $A^TA$ 是个正定矩阵(A中各列线性无关),或者半正定矩阵(A中各列线性相关),所以其特征值 $\lambda$ 必然非负数,所以根号后能得到奇异值,根据$Av_i=\sigma u_i$ 可以求出剩下的 $u_i$ ,当然这是理论上的方法,实际上的数值计算过程中可以避免 $A^TA$ 这种大规模矩阵乘法。
回忆一下正定矩阵关于椭圆的那个例子
一个2x2正定矩阵对应二维空间一个椭圆(或者圆),其正交特征矩阵Q矩阵是对椭圆轴的旋转,特征值矩阵 $\Lambda$ 是对轴的拉伸,那么我们的SVD有同样的功效,而且有过之无不及,思考:
作为$A^TA$ 的正交特征矩阵$V$也是一个旋转矩阵,旋转的是圆的轴,$V^T$ 当然就是反方向旋转,$\Sigma$ 是对图形的拉伸,圆的拉成长的,接着 $AA^T$ 的正交特征矩阵也是旋转,整个过程如下图:
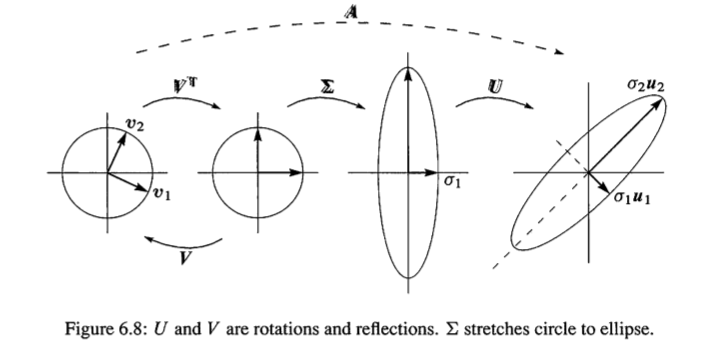
所以一个2x2的可逆矩阵,对一个圆的操作就是先拉伸,然后旋转。图中来自Cliff Long and Tom Herm
上面讲解了如何求V,同样的道理也可以求U,
$$
AA^T=(U\Sigma V^T)(U\Sigma V^T)^T\\
AA^T=(U\Sigma V^T)(V\Sigma U)\\
AA^T=U\Sigma^2 U^T
$$
U是$AA^T$ 的正交特征矩阵,也就是说同一个 $\Sigma^2$ 既是 $AA^T$ 又是 $A^TA$ 的特征值,所以上面那个疑问也得到了证明。
我们重新梳理一下这个证明过程,我们首先假设结论成立,来找到使结论成立的条件,也就是V和U矩阵,结果很理想的,我们找到了,所以原来结论成立,成立的条件就是我们刚找到的这两个矩阵(如果算上奇异值,可以说是三个矩阵),思考过程可以通过2x2构造那里来推出简单情况下,来验证我们的结论,然后再推广到任意矩阵。
至此SVD的基本来路我们已经算是摸着门了,所以可以深入开发下V和U矩阵,这两个矩阵是方阵,那么组成这些矩阵的向量门也是很有来历的,总结个表格,前面在第一部分有说过,就是reduced SVD那部分,这里在啰嗦一边:
| Number | in which Matrix(column) | in which Subspace |
|---|---|---|
| r | V | rowspcae of A |
| n-r | V | nullspace of A |
| r | U | column space of A |
| m-r | U | nullspace of $A^T$ |
前r列对应的是 $A^TA$ 和 $AA^T$ 的特征向量,因为其间的正交关系,所以SVD是没有什么问题的。
严格的证明:
$$
A^TAv_i=\sigma_i^2v_i
$$
这个是可以作为条件使用的,其成立的必然原因是 $A^TA$ 是正定或半正定矩阵,所以必然存在n个大于等于0的实数特征值,这样可以得到$v_i,\sigma_i$ ,在这个条件下我们目标是证明:存在$u_i$ 使得$Av_i=\sigma_i u_i$ 成立
对条件两边同时乘上 $v_i^T$ 后:
$$
v_i^TA^TAv_i=\sigma_i^2v_i^Tv_i\\
||Av_i||^2=\sigma_i^2
so:\\
||Av_i||=\sigma_i\\
$$
对条件两边同时乘A得到:
$$
AA^TAv_i=\sigma_i^2Av_i\\
set\,unit\,vector:\;u_i=\frac{Av_i}{\sigma}\\
AA^Tu_i=\sigma_i^2 u_i\\
$$
上面两个过程及其精妙,尤其是下面这个,用$u_i=\frac{Av_i}{\sigma}$ 进行置换后,得到$u_i$ 是$AA^T$ 的特征向量,然后得出结论,存在 $u_i=\frac{Av_i}{\sigma}$ 使得命题成立,而且u就是$AA^T$的特征向量,并且相互正交:
下面证明u相互正交:
$$
u_i^Tu_j=(Av_i)^T(Av_j)=v_i^T(A^TAv_j)=v_i^T(\sigma^2v_j)=0
$$
QED
然后老爷子在书上发话了,这是这本书最高潮的部分了,也是基础理论的最后一步了,因为他用到了所有的前面的理论:
- 四个子空间的维度(我们上面那个表)
- 正交
- 正交基来对角化矩阵A
- 最后得到SVD $A=U\Sigma V^T$
于是我写了一天这篇博客,比之前看书收获了更多,也可能有写纰漏,难免的因为水平有限,而且这个是比较精髓的部分,自然难度也比较大
搜索网络(Searching the Web)
这里讲了个应用,但是我实在不想写了,已经精疲力尽了,所以我打算后面选几个应用写,这个作为候选,这里略
Conclusion
线性代数的高潮算是来了,但是后面还有一个比较有意思的主题,也是很常用的,叫做线性变换,也可以作为切入线性代数的一个切入点,我们这个系列的博客是从线性方程组开始的,当然也可以通过线性变换引出矩阵,我们下一篇来讲解这个,待续。。