
Abstract: 人脸检测基本算法学习(迁移自CSDN)
Keywords: Adaboost,Haar-like,人脸检测,机器学习
人脸检测分析之 Haar-like,Adaboost,级联(Cascade)
写在前面的话
写在前面的牢骚话,作为一个非主流工程师,我专业与目前工作都与这些知识相隔十万八千里,所以,我所学习和实现的完全是因为兴趣,目前还研究学习的很浅,谈不上高深,所以还是要继续努力学习。希望和大家多交流,也欢迎伪大牛,假专家板砖伺候,也希望真大牛多指点(真大牛不会啰嗦一堆来显得他知道的多,哈哈),总之,本人还在菜鸟阶段,欢迎指教。0.0本文如有错误请及时留言指出,博主会在第一时间修改,确保不会对其他读者产生副作用。
人脸检测与识别
人脸识别系统主要包括四个组成部分,分别为:人脸图像采集及检测、人脸图像预处理、人脸图像特征提取以及匹配与识别。
人脸图像采集及检测
人脸图像采集:不同的人脸图像都能通过摄像镜头采集下来,比如静态图像、动态图像、不同的位置、不同表情等方面都可以得到很好的采集。当用户在采集设备的拍摄范围内时,采集设备会自动搜索并拍摄用户的人脸图像
人脸检测:人脸检测在实际中主要用于人脸识别的预处理,即在图像中准确标定出人脸的位置和大小。人脸图像中包含的模式特征十分丰富,如直方图特征、颜色特征、模板特征、结构特征及Haar特征等。人脸检测就是把这其中有用的信息挑出来,并利用这些特征实现人脸检测。
主流的人脸检测方法基于以上特征采用Adaboost学习算法,Adaboost算法是一种用来分类的方法,它把一些比较弱的分类方法合在一起,组合出新的很强的分类方法。
人脸检测过程中使用Adaboost算法挑选出一些最能代表人脸的矩形特征(弱分类器),按照加权投票的方式将弱分类器构造为一个强分类器,再将训练得到的若干强分类器串联组成一个级联结构的层叠分类器,有效地提高分类器的检测速度。
人脸图像预处理
人脸图像预处理:对于人脸的图像预处理是基于人脸检测结果,对图像进行处理并最终服务于特征提取的过程。系统获取的原始图像由于受到各种条件的限制和随机干扰,往往不能直接使用,必须在图像处理的早期阶段对它进行灰度校正、噪声过滤等图像预处理。对于人脸图像而言,其预处理过程主要包括人脸图像的光线补偿、灰度变换、直方图均衡化、归一化、几何校正、滤波以及锐化等。
人脸图像特征提取
人脸图像特征提取:人脸识别系统可使用的特征通常分为视觉特征、像素统计特征、人脸图像变换系数特征、人脸图像代数特征等。人脸特征提取就是针对人脸的某些特征进行的。人脸特征提取,也称人脸表征,它是对人脸进行特征建模的过程。人脸特征提取的方法归纳起来分为两大类:一种是基于知识的表征方法;另外一种是基于代数特征或统计学习的表征方法。
基于知识的表征方法主要是根据人脸器官的形状描述以及他们之间的距离特性来获得有助于人脸分类的特征数据,其特征分量通常包括特征点间的欧氏距离、曲率和角度等。人脸由眼睛、鼻子、嘴、下巴等局部构成,对这些局部和它们之间结构关系的几何描述,可作为识别人脸的重要特征,这些特征被称为几何特征。基于知识的人脸表征主要包括基于几何特征的方法和模板匹配法。 人脸图像匹配与识别
人脸图像匹配与识别:提取的人脸图像的特征数据与数据库中存储的特征模板进行搜索匹配,通过设定一个阈值,当相似度超过这一阈值,则把匹配得到的结果输出。人脸识别就是将待识别的人脸特征与已得到的人脸特征模板进行比较,根据相似程度对人脸的身份信息进行判断。这一过程又分为两类:一类是确认,是一对一进行图像比较的过程,另一类是辨认,是一对多进行图像匹配对比的过程。
以上摘自维基百科,虽然很普通的过程,却不失一般性,顾一个完整的系统,基本要靠这几步来完成,是否能开发出更好更快的而非这种结构的系统也是一个很值得深入的话题,比如一幅包含人脸和复杂背景的图片,是否能不通过分割而直接识别出人脸是谁,或者识别一个物体不是通过现有特征描述而是使用更符合人脑识别机制的其他描述,这些都值得我们深入研究。 其次,我们要区分人脸检测和人脸识别,所谓检测是区分人脸和非人脸,而识别是要得出已知人脸术属于谁,这从意义和用途上都有区别,而现在很多人将人脸识别和人脸检测混为一谈,包括知名专家(上过研究生的人都知道,有些老板根本不干活)。
或者我们可以更简单的把检测当做是分割(segment)的过程,即对物体进行识别最基本的过程:分割+识别。检测过程为输入一张复杂的图像,输出是其中人脸的部分,而识别是输入一张人脸的图像,输出的是这个人的身份信息或其他的只和此人有关的信息。
检测与识别算法
测算法和识别算法的结构多为:特征描述+分类算法。
特征描述给出不同物体间不同的表示,该描述应该具有一定的性质,包括特异性,即不同物体特征值不同,并对旋转,缩放,光照,形变等不敏感。好的特征描述能够使识别更加准确,而好的分类算法也能提高准确度和计算速度,分类算法多为机器学习算法,即需要训练,才能用于识别工作。
目前比较常用的特征描述有:Haar-like,LBP,SIFT,SURF等常见特征描述。
人脸识别算法分类:
- 基于人脸特征点的识别算法(Feature-based recognition algorithms)。
- 基于整幅人脸图像的识别算法(Appearance-based recognition algorithms)。
- 基于模板的识别算法(Template-based recognition algorithms)。
- 利用神经网络进行识别的算法(Recognition algorithms using neural network)。
人脸识别理论分类:
- 基于光照估计模型理论:提出了基于Gamma灰度矫正的光照预处理方法,并且在光照估计模型的基础上,进行相应的光照补偿和光照平衡策略;
- 优化的形变统计校正理论:基于统计形变的校正理论,优化人脸姿态;
- 强化迭代理论:** 强化迭代理论是对DLFA人脸检测算法的有效扩展;
独创的实时特征识别理论:该理论侧重于人脸实时数据的中间值处理,从而可以在识别速率和识别效能之间,达到最佳的匹配效果;
详细可参考网址: http://www.face-rec.org/algorithms/ 所列出的常见算法。

机器学习
机器学习在人脸识别中使用广泛,其理论和应用都及其有价值,Adaboost就属于一种机器学习算法,直白的理解机器学习就是通过用已知样本来不断的优化算法中的可变系数,最后来建立一种机制,该机制能够达到我们想要分类或者识别的目的。当然这不是官方定义,而是我的理解,但机器学习算法的理论基础多半是优化,寻求最优解,具体知识可以参考其他资料,这里不再赘述。
Haar-like特征点
Haar-like特征点,是一种简单的特征描述,其理论相当容易理解,就是按照下图的模式来计算白色窗口的像素总和和黑色窗口像素总和的差(C中的计算为白色窗口的像素总和减去黑色窗口的像素总和的2倍),这是常用的几种计算方式。
 4.1
4.1
后来又衍生了很多种Haar-like特征的计算方法,但计算法则不变,都是白色框内的像素总和减去黑色的,如下: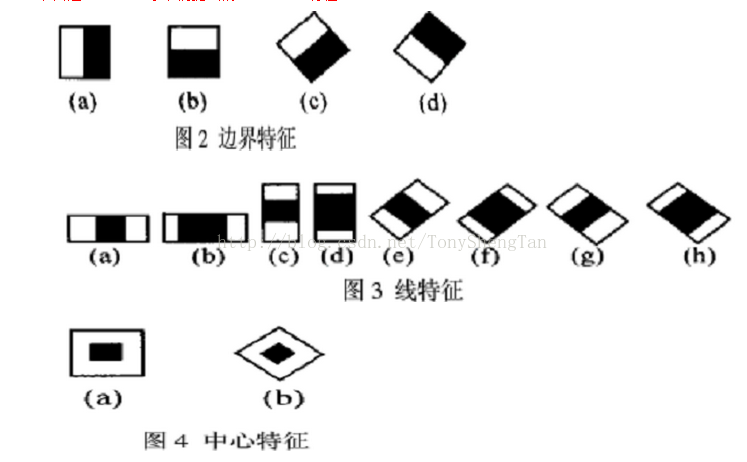 .2
.2
以下为图4.1描述的Haar-like特征在不同尺寸图像中的数量(窗口大小就是图像大小)  4.3
4.3
优化Haar-like计算速度的方法是使用积分图像,积分图像的简单描述为:对于单通道图像 $F(x,y)$ ,其积分图像 $G(x,y)$ 与 $F(x,y)$ 具有相同尺寸大小,且点 $G(x_0,y_0)$ 处的值为 $SUM(F(i,j))$ 其中 $(i<=x_0&&j<=y_0)$ ,公式描述为下图,ii为积分图像G,i为原始图像F。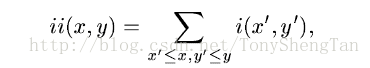
所以我们有下列结构,点4的值为ABCD区域像素值的总和,1为A区域的像素值总和,2,3同理: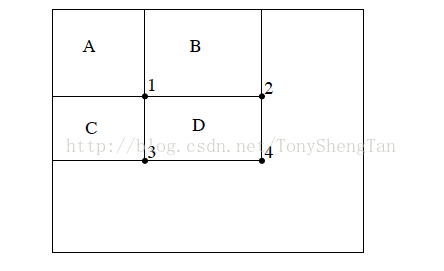 4.4
4.4
所以区域D内像素和的值为:4-2-3+1,这个不难理解,因为2,3都包括1,所以多减了一次,要加回来。这样就很容易的计算局部区域的像素和,从而方便了Haar-like特征值的求解。
Adaboost
首先我们来介绍强分类器和弱分类器:这类似于两个鉴宝工程师,一个经验丰富,准确率高我们称为老手,一个刚刚毕业准确率低,我们称为新手,但他们和我们这群普通人的区别在于,如果有100万件古董和赝品,老手的正确鉴别率能达到90万件,而新手的鉴别率为70万件,而我们接近以随机方式给出答案,顾准确率在50万件左右。这里的老手对应强分类器,新手对应弱分类器,而我们对应瞎猜分类器(这句掐了别播)。
Adaboost以同样原理工作,其对与已知分类的数据样本给出不同的阈值,各个阈值就是弱分类器,其准确率必须大于50%,其中样本对应的权重不同,其准确率为样本加权后的准确率,例如一百个数据,第一个数据占所有数据权重的百分之60,顾只要这个数据分类正确,其准确率肯定达标,相反肯定不达标。
首先来看阈值选择: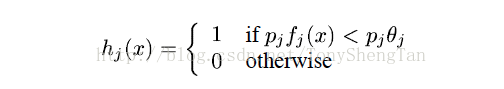
这个式子中,$p_j$ 为 $\pm 1$ ,其作用就是表示是大于号还是小于号,而西塔为我们给出的阈值,假设为新手A,例如,对于古董的一个特征f值(例如材料密度),我们可以给出其大于阈值是为古董或者小于阈值为古董。当然这个分类并不准确,因为有的赝品也可以用类似真品的材料仿造。这样新手A使用密度测定法给出了一个大于60%的识别率,同时按照A的识别率给A一个发言权重Alpha( $0<\alpha<1$ ),为了帮助新手,这100万件古董的主人(对真伪完全确定的人)决定,把新手A分错的真品和赝品调整权重(即调整密度,这都非人力所及的事啊,博主太能扯。。),然新手B来分类,依然以密度分类,然给B一个发言权重,依次迭代新手C,D,E,F,并得到各自的发言权重Alpha。最后当所有新手都有权重时,我们来最后进行表决,拿来另外一件古董(测试样本),让这些新手投票,这件宝贝是还是不是真品,每个人投票后加权( $\alpha$ ),如果加权以后超过半数,则这件判断为真品,否则为赝品。这就是完整的Adaboost过程。 先看下实际中的数据运算过程:
step 0:原始数据,解释下最左边一列,编号为数据编号,数值为特征值(上例所说的密度),标签为分类(两类,1,0,上例中的正品和赝品),权重(每个样本的“重要性”,或者说对整体的影响,初始化:正样本为1/2m,m为正样本数,负样本为1/2n,n为负样本数)。
step 1:寻找一个阈值 $\theta=4$ ,使大于(或小于,这里为小于)其的为正样本,另一侧为负样本,这里有阴影的为正样本划分区,另外为负样本区,负样本区中的正样本为分类错误的样本(9,10)这时,我们增加其权重(其实是减小正样本的权重,但归一化后就与增加负样本的效果一致了),并计算这个阈值的误差error=0.142857。 这样我们就得到了第一个弱分类器,其theta=4,方向是小于阈值为正,话语权为 $\alpha=1.791759$ 。大家会有疑问,4这个阈值哪来的,我是通过穷举所有的阈值,得出error最小的阈值,也有其他算法,可以参考原文【】。
step2:第二部重复上一步,得到error,theta,alpha,更新权重 step3:继续重复
step3:继续重复
step 4: . . . .
step n:完成循环要求的次数,或其他推出条件成立时,推出,保存所有theta,alpha和error
下面给出原文中的算法步骤:
上述算法中,表示误差的error求出权重使用了 $\frac{e}{(1-e)}$ ,这里我们可以知道,如果e大于0.5那么整个算法就会出现问题,因为不是按照思想继续放大错分样本的权重而是减小其权重,所以这里应该有一定的说法。
具体实现代码:
1 |
|
级联cascade
其实我在实现Adaboost时没遇到什么困难,相反,在实现级联时却有点概念不清,首先来看第一张图:
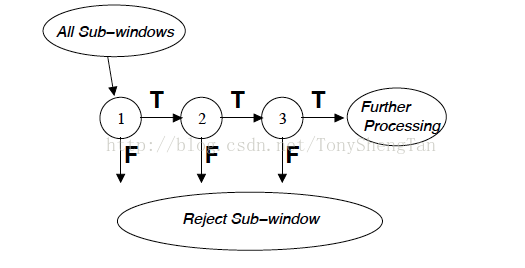 7.1
7.1
其想表明的时将一组(或一个)强分类器作为一个节点,来串联成一个级联结构,类似于逻辑上的“AND”即如果一个子窗口被判定为人脸,那么其必须对于所有分类器都为真,但是,我不懂的问题是,节点内部的那一组强分类器是什么结构,怎么组织的,这个目前还没搞懂,所以级联没有实现出来,也希望大牛指点下。
级联的基本步骤如下: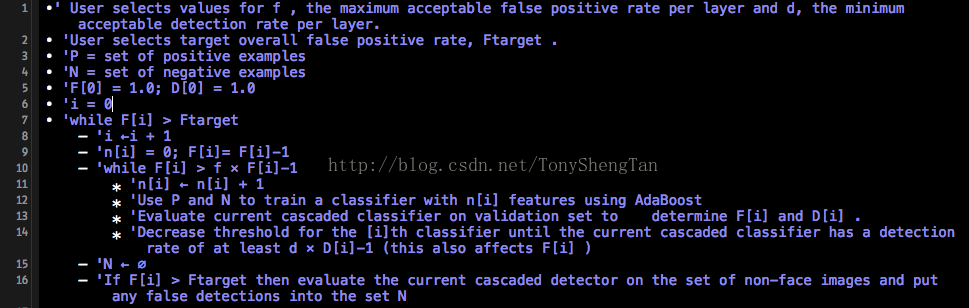 7.2
7.2
翻译成中文为: 7.3
7.3
这里的时人脸的Harr-like特征集作为训练样本,识别率为D和误识率F,解释下false positive和false negative,第一个字面翻译为错误的positive就是本来不是目标,却分类成目标,后一个意思是本来是目标,结果当成了非目标。
还有疑问就是选择特征方面,如何选择一个Harr-like特征来训练一个分类器,因为有很多Haar-like,而其中只用了一部分,用哪些?
每一层都用到Haar-like,但怎么选择用哪个Haar-like,而且上一层用过的Haar-like特征是否还能继续用于这一层。其他部分相对来说比较容易,比如把测试集中的false positive放到下一步的训练集中,减少Adaboost中的阈值个数来提高识别率等。
相关试验数据
相关试验数据由原论文中截取,因为博主还没实现级联,而且笔记本电脑训练起来也很伤神,所以只给出一个性能图,以供参考: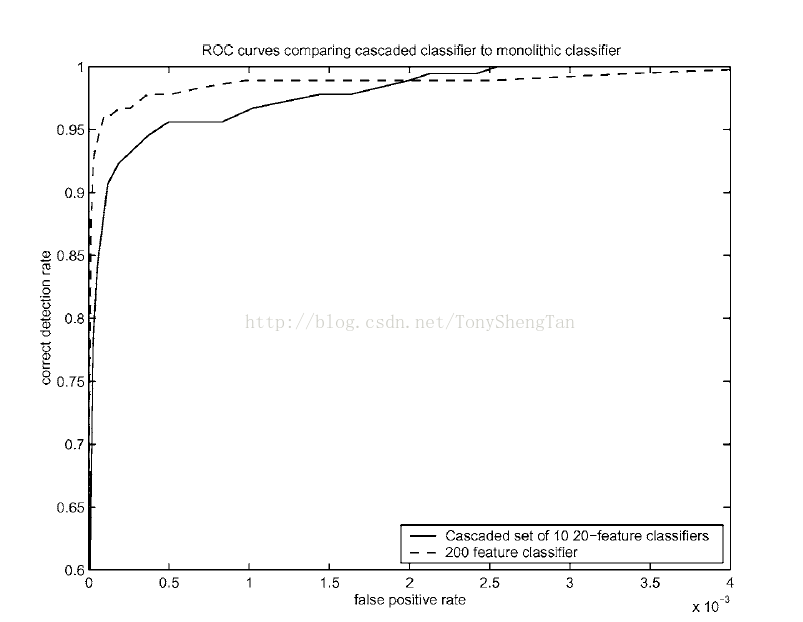 8.1
8.1
参考
《Rapid_Object_Detection_using_a_Boosted_Cascade_of_Simple_Features》
《Robust Real-Time Face Detection》
下载附件
http://download.csdn.net/detail/tonyshengtan/8251621
