
Abstract: 机器学习数据预处理的小总结
Keywords: 数据,预处理
训练数据选择血泪史
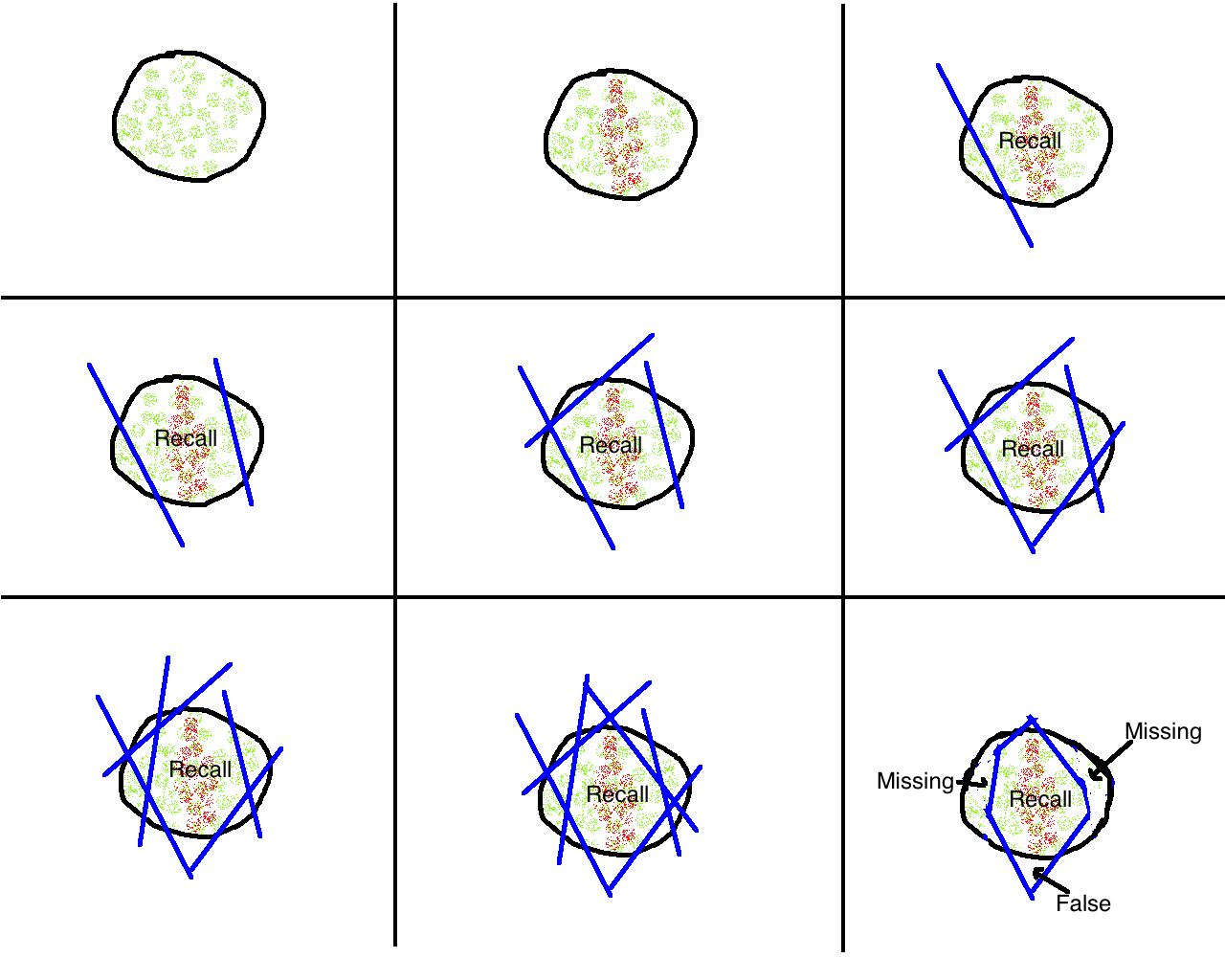
这一幅图就能完整说明整个训练过程,说明
从左到右,从上到下的顺序,表明整个训练
- 图一中黑圈绿点是目标pattern或者feature的真实(ground truth)分布(应该是更多维我只能画二维的)
- 图二红色点是训练时选出的训练样本,可见其覆盖不广泛
- 图三是训练过程,蓝色实线代表分类器(线性的,也可以是非线性的)
- 图四到图八是完整的训练过程
- 图九为最后训练结果,包括recall部分,missing的部分,以及false的部分
整个过程最直观的外在表现就是随着训练不断深入,模型的在测试集上的Recall逐渐变差
如果继续复杂化训练模型,会产生严重的过拟合
解决方法:
- 样本复杂化,尽量覆盖整个分布
- 更多样本