
Abstract: 学习LeNet的论文总结Stochastic Gradient 与 Batch Gradient 的比较 以及收敛速度
Keywords: Stochastic Gradient,Batch Gradient,Faster Convergence
LeNet论文解读
Stochastic Gradient vs Batch Gradient
基于梯度的算法可以使用两种中的一种来更新参数
- 第一种叫做Batch Gradient
- 另一种叫Stochastic Gradient
Batch Gradient(BG)
这是最传统的一种梯度算法,梯度是通过对所有训练样本进行计算得出,然后更新所有参数。
Stochastic Gradient(SG)
是一种局部的,包含噪声的梯度估计法,这种方法只计算一个或者一组较小数量的训练样本来估算梯度,之后更新所有参数。
样本一般算计选取,或者先把样本随机排队,然后逐个(组)使用。
随机梯度下降在中国著名讲师Ng的公开课中也是最先提到的两种方法之一,另一种就是Batch Gradient,在随机梯度下降中,参数更新更快,单次更新方向虽然不是朝向全局最小方向,但大量迭代后,能够快速收敛到最优解。
尤其是大数据量的时候,SG具有显著优势
BG vs SG
本文表示,截止到论文发表时,原理未知,但是可以通过简单的实验来测试得出一个直观上的认识,下面简单叙述一下实验:
受限在一个完整的训练集里又完全一毛一样的两个子集组成,例如全集是A,子集 a={1,2,3,4} ,那么全集A就是{1,2,3,4,1,2,3,4}。
方案一:通过全集来估计梯度,很明显,大量pattern(pattern被翻译成模式,我觉得不太直观,还不如就叫pattern,可以理解为每个样本特有的一些性质)是重复的。
方案二:使用SG,每次随机选A的一半来更新梯度,与方案一在同样的运行时间,方案二迭代了接近两次。在数据量方面,有效信息,方案二并不比一少很多。
这种方式可以范化到所有包含重复Pattern的训练样本的情况。
其他方法
另外还有很多优化方法:
二阶算法:
1.例如Gauss-Newton(GN)方法或者Levenberg-Marquardt(LM)方法
- Quasi-Newton 方法包含Broyden-Fletcher-Goldfarb-Shanno(BFGS) 方法,Limited-storage BFGS(ls-BFGS)算法
- Conjugate Gradients(CG)算法的变种
很遗憾,以上方法在大训练样本的情况下都不稳定。
- GN和LM是 $O(N^3)$ 的时间复杂度,N是参数数量
- QN是 $O(N^2)$ 的时间复杂度
- ls-BFGS和CG是 $O(N)$ 的复杂度
以上算法的收敛速度取决于选择下降的方向是否准确,而要想准确就要使用全体数据(BG)
对于大量样本,以上方法的加速结果远不如SG的效果,一些研究者想使用小batch的cg算法,目前没啥效果。
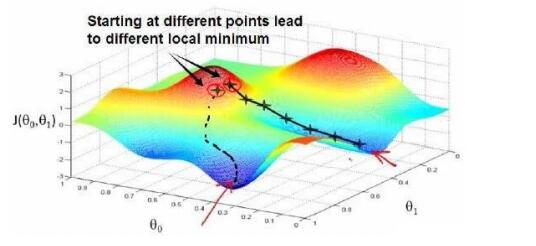
作者的经验是使用随机方法来优化参数,在error surface上寻找最小值:
error surface就是:
Conditions for Faster Convergence
“Gradient Based Learning Applied to Document Recognition “
LeCun, Y Bottou, L Bengio, Y Haffner, P
学习LeNet,从附录开始,附录介绍了一些非常有用的基础知识,简单总结一下
压缩函数
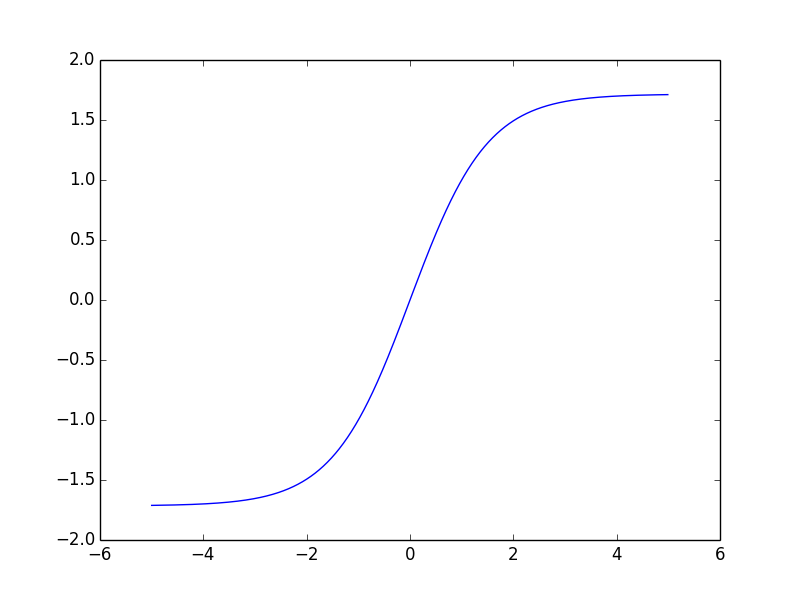
Squashing function,压缩函数,定义域的范围远远大于值域,这样的函数就是压缩函数,神经网络最常用的就双曲正切函数:
$$f(a)=A tanh(Sa)$$
$$tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}$$
本文指出:
收敛速度
对称函数能产生更快的收敛,当权重weights非常小的时候,收敛将变得及其的缓慢收敛变慢的原因:在权重空间,学习动力(learning dynamic)是一个固定点,或者,进入鞍点,各个方向都是下降方向。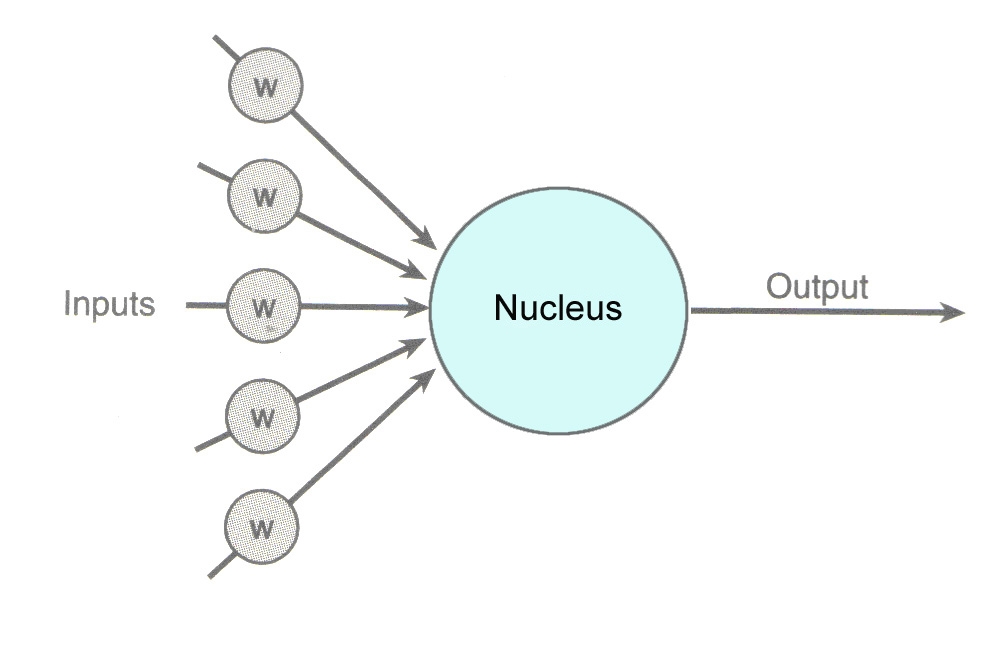
上图为最简单的单元,包含输入weights和激活函数(压缩函数),其反向传导(如不有疑问查询BP神经网络相关知识)公式为:
$\delta_i^{(l)}=(\sum_{i=1}^{s_{l+1}}W^{(l)}_{ji}\delta^{l+1}_j)f’(z_i^{(l)})$$
观察公式可以得出,如果导数过小或者weight过小都会使更新距离变短,这样会使收敛速度变慢。
把激活函数设置成A=1.7159,S=2/3 ,$f(1)=1$,$f(-1)=-1$这么做背后的原因是在正常的处理情况下,压缩的结果会在1附近,这样神经网络的表现将会非常简单。并且f的二次导数在1和-1达到最大值,这使得优化朝向学习最后的阶段(权重收敛的全局最优解)。
观察下图:
tanh函数图像: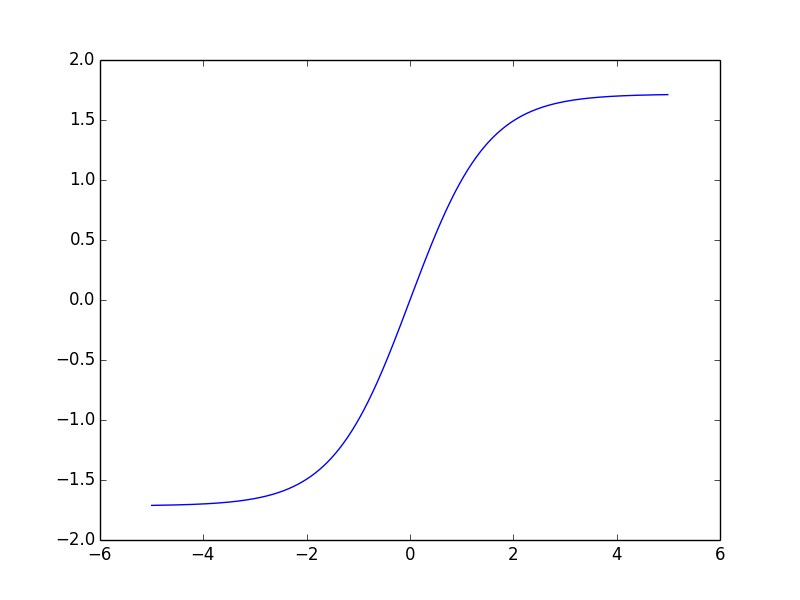
tanh函数一阶导数: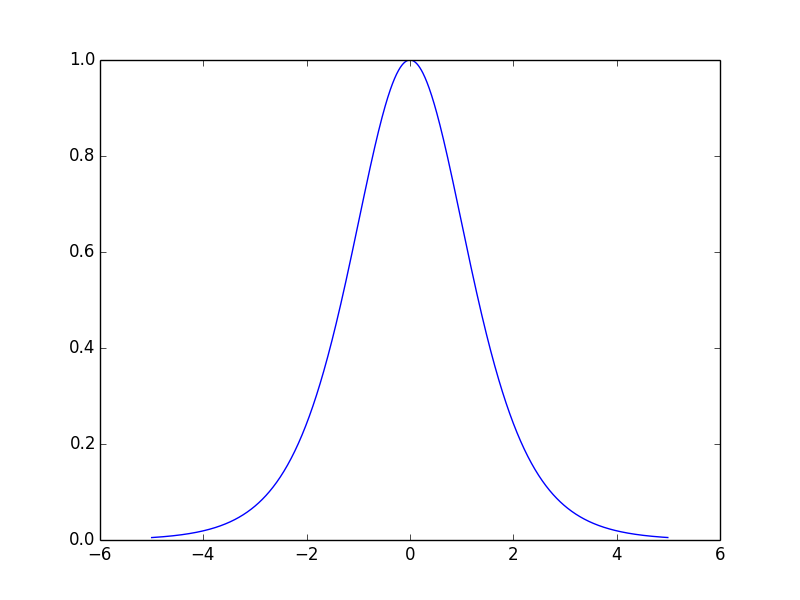
tanh函数二阶导数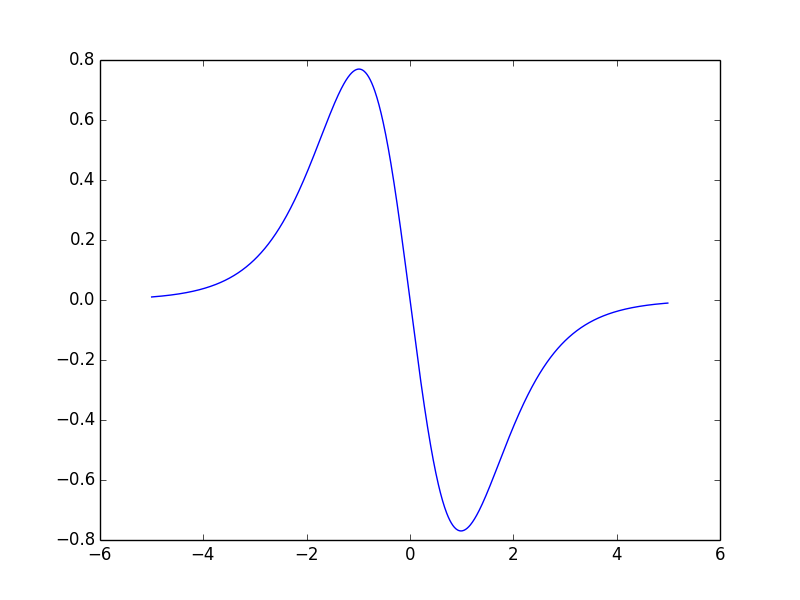
二阶导数绝对值在+-1附近最大,二阶导数最大意味着一阶导数最大,这样就意味着梯度(一阶导数)在这附近有最大的变化,这样使得损失函数顺着下降的方向走去。。
参数初始化
特别选择的参数只是能够方便一些,并不影响最终结果
参数初始化:无论是人手工设计还是随机设置,都不太影响结果;
训练开始之前,对所有权重进行均匀分布随机初始化(在 $\frac{2.4}{F_i}$ 和 $\frac{-2.4}{F_i}$ 之间,F为所有连接的总数fan-in,扇入)
图中每一个w所在的输入都被称为一个fan-in(像扇子一样的输入),图中有五个扇入。
如果一些连接有相同的权重,那么问题就变得复杂,但本文的网络(卷积层)对应同一Fan-in的所有权值都是share的,通过fan-in来划分的原因是我们希望加权和的初始化标准差在一个范围内,并且这个加权和落在激活函数的正常工作区。如果初始化权值太小,梯度会很小,优化速度将会变慢,如果权值过大,激活函数会饱和,梯度也会很小。当输入相互独立的时候加权和的标准差的比例类似于输入数量的标准差,当输入高度相关的时候,加权和的标准差接近于输入数量的线性关系。我们选择第二种假设,因为输入往往高度相关
卷积神经网络第一大特点:权值共享,也就是说同一fan-in,在整个过程中值是一样的,将fan-in初始化到一个范围内,可以控制其结果落在激活函数的一定区域内:
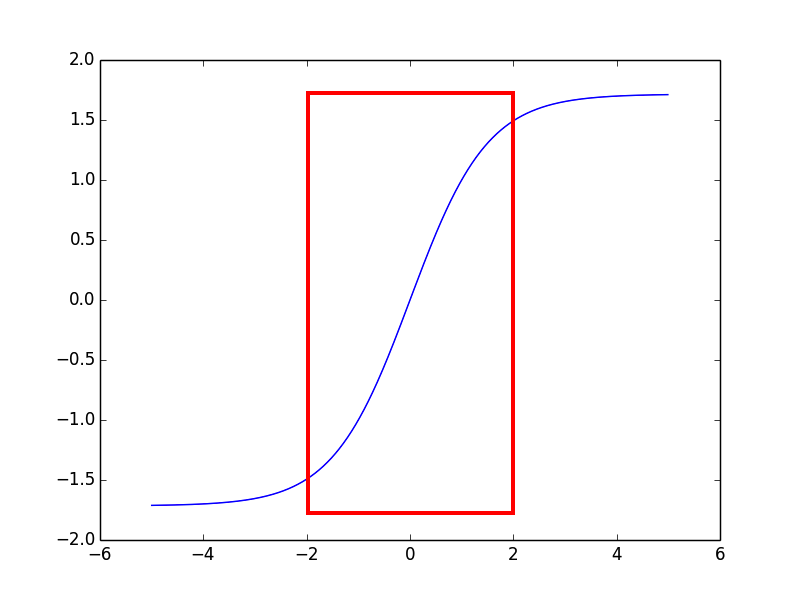
因为落在外面区域将会使得激活函数过大,一阶导数过小。
按照原文所说,如果输入数据相关性强,输出大概呈现线性关系,如果输入不相关,输出呈现平方根关系。因为输入是图像的一个区域,高度相关,所以其结果大致呈线性。
本系列还有后续,慢慢期待
总结
还是中期读论文的博客风格,有点说教的感觉,大家可以在看论文看不太懂的时候来这里找找看有没有你需要的知识。