Abstract: In this paper we present a system, called FaceNet, that directly learns a mapping from face images to a compact Euclidean space where distances directly correspond to a measure of face similarity
提出一个系统,此系统能将人脸图片直接映射到欧几里得空间的一个向量,这些向量之间的距离能直接度量人脸之间的相似度
Keywords: 人脸识别,FaceNet,GoogleNet
FaceNet论文阅读
从老的wordpress转移过来,之前一年一直在做人脸识别算法研究,现在回头看看too young too simple,但是这些经历也算对自己的有很多帮助,认清自己的水平,知道自己什么方面比较差,这样也算是有所帮助
Our method uses a deep convolutional network trained to directly optimize the embedding itself, rather than an intermediate bottleneck layer as in previous deep learning approaches.
深度卷积网络直接优化embedding,而不是以往深度学习的连接层
To train, we use triplets of roughly aligned matching / non-matching face patches generated using a novel online triplet mining method
在训练过程中,我们使用粗略对齐的匹配和非匹配人脸区块的triplets,这些triplets是通过一个出色的在线triplet挖掘方法得到的
128-bytes per face
每个人脸使用128维向量表征
Introduction
The network is trained such that the squared L2 distances in the embedding space directly correspond to face similarity: faces of the same person have small distances and faces of distinct people have large distances.
网络输出embedding ,在embedding空间直接描述人脸的相似程度,同一个人有较近的距离,不同的人有较远的距离
Previous face recognition approaches based on deep networks use a classification layer [15, 17] trained over a set of known face identities and then take an intermediate bottleneck layer as a representation used to generalize recognition beyond the set of identities used in training
之前人脸识别给予深度网络的使用一个分类器层,独立地使用一组已知的人脸来训练,然后使用一个中间瓶颈层作为一个人脸的表征,来用于识别不同于训练样本类别的人脸
The downsides of this approach are its indirectness and its inefficiency: one has to hope that the bottleneck representation generalizes well to new faces; and by using a bottleneck layer the representation size per face is usually very large (1000s of dimensions)
以前识别算法的劣势在于不直接和低效:其必须希望瓶颈层的表征对于新的人脸有好的范化能力;使用瓶颈层的表征的维数非常大,1000或更多。
Some recent work [15] has reduced this dimensionality using PCA, but this is a linear transformation that can be easily learnt in one layer of the network
一些最近的工作为了减少维数使用pca降维,但是其是一个线性变换,可以在任意一层网络层轻松学到。
FaceNet directly trains its output to be a compact 128-D embedding using a triplet-based loss function based on LMNN [19].
FaceNet直接训练他的输出使其达到紧凑的128维embedding,使用基于LMNN 【19】的triplet 损失函数
Our triplets consist of two matching face thumbnails and a non-matching face thumbnail and the loss aims to separate the positive pair from the negative by a distance margin
triplet包含两张匹配的人脸,和一张非匹配的人脸,目的是用一对正例,和一对负例,并保证ap和an之间差一个margin(空隙,空间)
The thumbnails are tight crops of the face area, no 2D or 3D alignment, other than scale and translation is performed
样本内容为人脸紧凑的切割,不需要任何2D,3D的对齐,尺度变换,和其他变换
Choosing which triplets to use turns out to be very important for achieving good performance and,
选择triplets很重要
inspired by curriculum learning [1], we present a novel online negative exemplar mining strategy which ensures consistently increasing difficulty of triplets as the network trains.
受到【1】的启发,我们提出了一个新奇的在线负样本挖掘策略,来确保在网络训练过程中持续增加triplets的难度
To improve clustering accuracy, we also explore hard-positive mining techniques which encourage spherical clusters for the embeddings of a single person.
为了提高聚类正确性,使用hard正样本挖掘技术,来确保单个人脸的EMbedding约束在球形内
可以处理以前觉得很难的样本,如下:

RelatedWork
Similarly to other recent works which employ deep networks [15, 17], our approach is a purely data driven method which learns its representation directly from the pixels of the face. Rather than using engineered features, we use a large dataset of labelled faces to attain the appropriate invariances to pose, illumination, and other variational conditions.
类似于15,17,我们的应用是纯粹的数据驱动的方法,使用人脸图片的像素作为输入,而不是使用人工构建的特征,使用大量的标记后的人脸数据使网络对于pose,illumination和其他conditions稳定。
本文讨论了两种网络架构:
1:The first architecture is based on the Zeiler&Fergus [22] model which consists of multiple inter-leaved layers of convolutions, non-linear activations, local response normalizations, and max pooling layers
2:The second architecture is based on the Inception model of Szegedy et al. which was recently used as the winning approach for ImageNet 2014 [16]
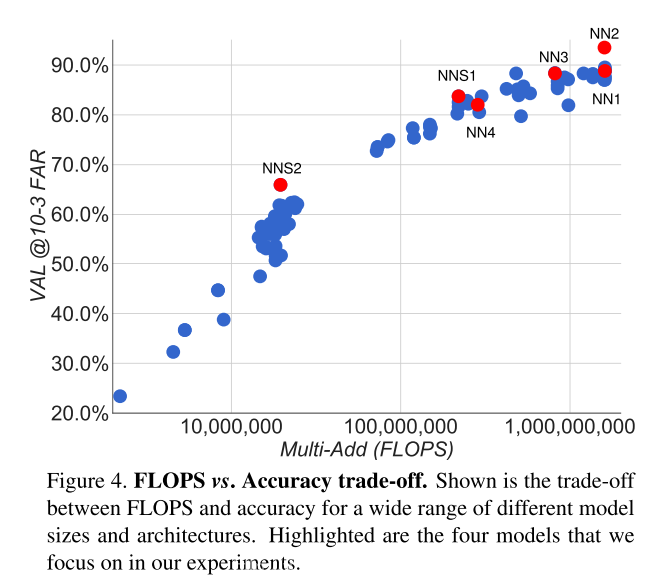
We have found that these models can reduce the number of parameters by up to 20 times and have the potential to reduce the number of FLOPS required for comparable performance
以上两种网络结构能减少20倍以上的参数,并且能潜在的减少FLOPS的数量(与同类的网络)
近期人脸识别工作一大堆,挑几个代表性的说:
The works of [15, 17, 23] all employ a complex system of multiple stages, that combines the output of a deep con-volutional network with PCA for dimensionality reduction and an SVM for classification:
深度学习+PCA+SVM
Zhenyao et al. [23] employ a deep network to “warp” faces into a canonical frontal view and then learn CNN that classifies each face as belonging to a known identity. For face verification, PCA on the network output in conjunction with an ensemble of SVMs is used.
使用深度网络把脸弄成正面视角的,然后训练网络,verification的时候PCA网络输出,然后用svm分类
Taigman et al. [17] propose a multi-stage approach that aligns faces to a general 3D shape model. Amulti-class network is trained to perform the face recognition task on over four thousand identities.
多阶段应用来align人脸,得到3d的形状,然后训练多类网络来进行识别
Sun et al. [14, 15] propose a compact and therefore relatively cheap to compute network. They use an ensemble of 25 of these network, each operating on a different face patch.
小型紧凑的网络模型,易于计算,共使用25个这样的网络,每个网络对应于人脸的不同区块。
The verification loss is similar to the triplet loss we employ [12, 19], in that it minimizes the L2-distance between faces of the same identity and enforces a margin between the distance of faces of different identities.
Verification loss 类似于triplet loss 我们引用自12,19的方法,最小化L2距离,在同一个人之间和不同人之间的margin。
Method
two different core architectures:
- The Zeiler&Fergus [22] style networks
the recent Inception [16] type networks
Given the model details, and treating it as a black box (see Figure 2), the most important part of our approach lies in the end-to-end learning of the whole system.
网络模型当做黑盒如下图,我们主要关心更重要的。端对端的系统学习
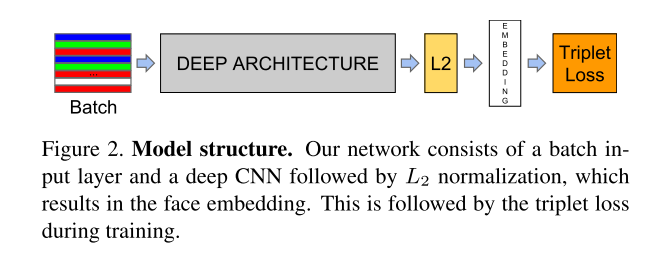
To this end we employ the triplet loss that directly reflects what we want to achieve in face verification, recognition and clustering.
在一端,我们使用triplet loss 直接反应我们想要在人脸分辨,识别,聚类中达成的目标
Namely, we strive for an embedding f(x), from an image x into a feature space Rd,
我们使用embedding , f(x)直接将图像从x域映射到特征空间R(d维),
The triplet loss, however, tries to enforce a margin between each pair of faces from one person to all other faces. This allows the faces for one identity to live on a manifold, while still enforcing the distance and thus discriminability to other identities
Triplet loss 试图去注意在正样本对和负样本对之间的margin,这使得同一类的人脸存在于多种情况,同时也关注其间的距离,因此对于其他类可分辨。
Triplet Loss
Here we want to ensure that an image
我们要确保对于一张图:
1.of a specific person is closer to all other images
同一人的不同图片距离$x_i^p(positive)$
2.of the same person than it is to any image
母样本,或者称为锚点$x_i^a(anchor)$
3.of any other person
对于其他样本(负样本)$x_i^n(negative)$
我们希望确保同一人的ap相近,ab距离远,如下图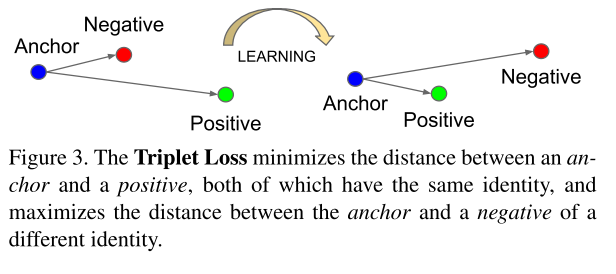
因此,我们希望:
$$
||x_i^a-x_i^p||_2^2+\alpha < ||x_i^a-x_i^n||_2^2 ,\forall(x_i^a,x_i^p,x_i^n)\in\tau
$$
alpha表示margin在正例对和负例对之间的距离,T是一组可能的triplets在训练数据集中的。基数为N。
最小化的Loss:
$$\sum_i^N[||f(x_i^a)-f(x_i^p)||^2_2-||f(x_i^a)-f(x_i^n)||^2_2+\alpha]_{+}$$
Generating all possible triplets would result in many triplets that are easily satisfied (i.e. fulfill the constraint in Eq. (1)). These triplets would not contribute to the training and result in slower convergence, as they would still be passed through the network. It is crucial to select hard triplets, that are active and can therefore contribute to improving the model.
计算所有可能的triplet容易导致其中很多对于网络是无用的(网络可以轻易使其满足公式1),这些triplet对于训练和结果收敛速度没有贡献,选择难以分类的是重要的,这些是有吸引力的,而且可以帮助提高模型
Triplet Selection
In order to ensure fast convergence it is crucial to select triplets that violate the triplet constraint in Eq. (1)
为了快速收敛,选择违反公式1的triplet具有决定性作用。
选择hard-positive和hard-nagetive:
$$
argmax_{x_i^p}||f(x_i^a)-f(x_i^p)||^2_2
$$
$$
argmax_{x_i^p}||f(x_i^a)-f(x_i^n)||^2_2
$$
It is infeasible to compute the argmin and argmax across the whole training set.
在完整数据集上计算argmin和argmax是不可能的
Additionally, it might lead to poor training, as mislabelled and poorly imaged faces would dominate the hard positives and negatives. There are two obvious choices that avoid this issue:
尤其是,其可能导致不好的结果,因为有一些训练数据未准确标记,模糊的图片可能会决定hard positives或者hard negative,有两种明确的选择可以避免这两个问题:
Generate triplets offline every n steps, using the most recent network checkpoint and computing the argmin and argmax on a subset of the data.
每N步后线下寻找triplet,使用最近生成的网络,计算argmin和argmax在数据的一个子集上
Generate triplets online. This can be done by selecting the hard positive/negative exemplars from within a mini-batch.
在线获取triplet,通过从一个小的batch中选取hard positive或者hard negative样本。
Here, we focus on the online generation and use large mini-batches in the order of a few thousand exemplars and only compute the argmin and argmax within a mini-batch.
这里我们专注于在线获取,使用大的mini-batches包含几千个样本,而且只计算argmin和argmax在这个mini-batche上
To have a meaningful representation of the anchor-positive distances, it needs to be ensured that a minimal number of exemplars of any one identity is present in each mini-batch. In our experiments we sample the training data such that around 40 faces are selected per identity per mini-batch. Additionally, randomly sampled negative faces are added to each mini-batch.
为了获得一个有意义的AP距离的表达,其需要确保在每一个mini-batch任一类必须有少量的样本被选出,我们的经验是我们在训练样本中采样大约40个人脸图像每个人每个mini-batch。此外,随机采样负样本人脸,加入到每一个mini-batch
Instead of picking the hardest positive, we use all anchor-positive pairs in a mini-batch while still selecting the hard negatives.
我们选取mini-batch中所有的ap对而不是选择最难的ap对。但是我们依然选择最难的an对
We don’t have a side-by-side comparison of hard anchor-positive pairs versus all anchor-positive pairs within a mini-batch, but we found in practice that the all anchor- positive method was more stable and converged slightly faster at the beginning of training.
我们没有对mini-batch中的所有ap对进行side-by-side的hard程度比较,但是我们的经验是所有的ap对都使用能够增强收敛稳定性和速度,在训练初始阶段。
We also explored the offline generation of triplets in conjunction with the online generation and it may allow the use of smaller batch sizes, but the experiments were inconclusive.
offline和online结合,这种方法允许使用更小的batch大小,但是结果是没啥结果。。
Selecting the hardest negatives can in practice lead to bad local minima early on in training, specifically it can result in a collapsed model (i.e. f(x) = 0). In order to mitigate this, it helps to select xni such that
选择最难的AN对可以在训练早起引导向局部最小值,特别的,他能勾引起模型塌陷,为了避免这种情况,我们选取n的时候要满足以下条件:
$$||f(x_i^a)-f(x_i^p)||^2_2<||f(x_i^a)-f(x_i^n)||^2_2$$
We call these negative exemplars semi-hard, as they are further away from the anchor than the positive exemplar, but still hard because the squared distance is close to the anchor-positive distance. Those negatives lie inside the margin α.
我们称这些negative为semi-hard,因为他们距离anchor比positive远,但是还难以区分,因为距离还是比较接近ap距离,这些negative在margin alpha内!
As mentioned before, correct triplet selection is crucial for fast convergence.
选好triplet能加速收敛
On the one hand we would like to use small mini-batches as these tend to improve convergence during Stochastic Gradient Descent (SGD) [20].
一方面我们使用小的mini-batch加速收敛,使用sgd
On the other hand, implementation details make batches of tens to hundreds of exemplars more efficient.
另一方面,执行细节使得样本的几十到几千的batch更有效
The main constraint with regards to the batch size, however, is the way we select hard relevant triplets from within the mini-batches.
Batch size 的主要的约束是我们从mini-batches选择hard triplet的方式
In most experiments we use a batch size of around 1,800 exemplars
Batch size大约1800个样例
Deep Convolutional Networks
In all our experiments we train the CNN using Stochastic Gradient Descent (SGD) with standard backprop [8, 11] and AdaGrad [5]. In most experiments we start with a learning rate of 0.05 which we lower to finalize the model. The models are initialized from random, similar to [16], and trained on a CPU cluster for 1,000 to 2,000 hours. The decrease in the loss (and increase in accuracy) slows down drastically after 500h of training, but additional training can still significantly improve performance. The margin α is set to 0.2.
使用BP算法和SGD优化来训练CNN,AdaGrad用来调整步长,初始化步长为0.05,模型随机初始化,类似于16,使用cpu集群训练了1000-2000小时,500小时后训练效果变化变慢,但还是继续训练还是有效果的,alpha选择0.2
The first category, shown in Table 1, adds 1×1×d convolutional layers, as suggested in [9], between the standard convolutional layers of the Zeiler&Fergus [22] architecture and results in a model 22 layers deep. It has a total of 140 million parameters and requires around 1.6 billion FLOPS per image.
The second category we use is based on GoogLeNet style Inception models [16]. These models have 20× fewer parameters (around 6.6M-7.5M) and up to 5×fewer FLOPS(between 500M-1.6B).