
Abstract: 关于python网络爬虫的入门
Keywords: 爬虫,python
爬虫介绍
数据收集过程
我们平时访问网络使用的主要是浏览器,其实浏览器和编译器以及操作系统这三大软件应该是软件界比较厉害的三种工具了,当然你要说出几个其他的比如Photoshop什么的当然,这也厉害,但是和我们CS相关的这三个应该是最顶级的工具了。
我们平时和网络上的数据进行信息交换主要通过浏览器,比如我们从网上找一些图片,或者一些新闻,这个过程人工进行是很慢的,所以我们的党政机关有不少人专门负责上网看新闻(铛铛铛,老乡,社区送温暖!)网站上的数据有时候我们想要,而且不止一部分而是全部,比如某个网站上全部的图片,我们需要用到的就是爬虫技术,之前不太了解爬虫,爬虫访问网站上的每一页的内容,识别出我们需要的数据,下载保存到本地,基本上就是我们使用爬虫的一般性过程,当然你如果就是为了统计点什么不需要把数据下载下来,也是可以的,这个过程大致的一个流程是: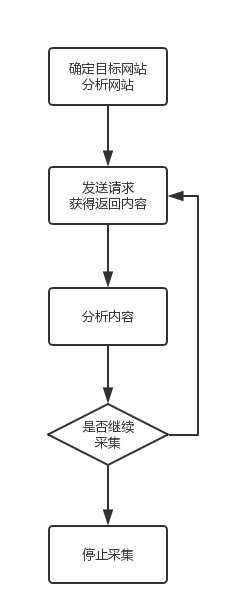
- 分析目标,这部分针对特定网站,如果你想写一个通用的爬虫,那么这部分可以不在考虑范围,而是考虑文件特征和如何判断网页是否已经处理过了;其次是考虑网站的结构和技术,动态网站,静态网站以及其他的特殊网站
- 获取网站回应,通过1中得到的信息,向服务器发送请求,当然这部分最好能模拟成和浏览器一样的请求,迷惑服务器正常返回所需要的信息,这部分是技术核心,也是你难点,因为各种网站结构不同,也有相应的防止爬虫的技术,所以,成为大神,这部分是关键
- 分析网站返回的内容,从服务器返回的内容中找到目标内容,进行分析和处理(这部分可能产生新的url作为爬取目标)
- 判断是否继续进行搜索,如果继续返回
- 打完收工
使用到的主要技术
那么我们要学会那些技术呢?
根据上面的爬取过程,根据我们前的知识,我们要用到但不限于以下技术: - HTML技术,JavaScript,CSS,Json等,这类知识主要跟前端有关,必须承认,我对这些知识的了解基本为零,所以边学边查
- 分析服务器返回内容,通过正则表达式,或者python 中的beautifulsoup等工具重建提取信息
- 保存主要用到数据库或者其他文件系统
上面这些技术是简单总结,可能不全,后面可能补齐
总结
技术类的东西可以从头学起,比如我们先学前端,再学服务器知识,再学网络等等,最后我们就变成了一个爬虫专家,但是我们的目标是数据专家,所以我们更多的时间应该放在数学和算法上,我们学爬虫,是为了服务于我们的数据分析算法的验证上,所以用到什么现学现卖,所以没有我们研究机器学习那么专业,我们主要用几个项目来学习过程
学习整个流程,当其中某些技术对于其他目标网站不奏效的时候,相应的调整,更换技术就能完成我们的新目标,我们主要参考下面这本书:

正则表达式则参考:

注意:正则表达式对于我们的机器学习和后面的开发用处较大,所以这部分内容更加详细